Visualisierung mit Streamlit
In diesem Abschnitt werde ich die Visualisierung der Daten mit Streamlit vorstellen. Streamlit ist ein Open-Source-Framework, das es ermöglicht, interaktive Webanwendungen direkt aus Python-Scripts zu erstellen. Streamlit eignet sich für eine schnelle und einfache Visualisierung von Daten und Modellen und ist daher ideal für Prototypen und kleinere Projekte. Für größere Projekte und Anwendungen empfehle ich jedoch andere Frameworks wie Flask oder Django.
Den ganzen Code der Streamlit-Anwendung findest du in meinem GitHub-Repository / datenflanke
Installation
Die Installation ist sehr einfach. Es wird nur Python benötigt. Mit pip kann Streamlit installiert werden:
pip install streamlit
Zum Starten der Anwendung wird folgender Befehl ausgeführt:
streamlit run app.py
Das war es schon. Streamlit startet einen lokalen Server und öffnet den Standardbrowser mit der Anwendung.
Beispiel: Spielerbewertung
Die Grundlegenden Prinzipien von Streamlit kannst du in der Dokumentation nachlesen.
Code Spielerbewertung.py
Beispielhaft für mein Projekt möchte ich dir die Seite der Spielerbewertung zeigen:
Zuerst die Imports:
import streamlit as st
import utils.helpers as helpers
import utils.plots as plots
from utils.chatbot import get_player_evaluation, get_player_evaluation_german
Dann lade ich die Daten und zwar so, dass die Daten beim ersten Aufruf der App aus der Datenbank geladen werden und dann im Cache gespeichert werden.
So ist sichergestellt, dass die Daten nicht bei jedem Aufruf der App neu geladen werden müssen.
# Daten laden
dataframe = helpers.preload_data()
Die Funktion zum Laden der Daten ist in der Datei utils/helpers.py definiert:
@st.cache_data
def preload_data():
# Load all data from the database
leagues = [
"bundesliga",
"premier_league",
"laliga",
"ligue_1",
"seria_a",
"champions_league",
"europa_league",
"bundesliga2",
"eredivisie",
"jupiler_pro_league",
"championship",
"liga_portugal",
"super_lig",
]
seasons = ["2022_2023", "2023_2024"]
# Initialize an empty list to store the data
data_list = []
for season in stqdm.stqdm(seasons):
for league in stqdm.stqdm(leagues, leave=False):
data = db.dataframe_from_sql(league, season, create_connection_string())
data_list.append({'league': league, 'season': season, 'data': data})
print("Data preloaded for", league, season)
# Create a new dataframe with columns league, season, and data
preloaded_data_df = pd.DataFrame(data_list)
return preloaded_data_df
Nun wird die Sidebar mit den Filteroptionen erstellt. Der Nutzer kann hier die Liga, die Saison, die Position, den Spieler und die Qualität auswählen. Über die Funktion get_data_by_league_and_season wird der Dataframe für die gewählte Liga und Saison aus dem vorgeladenen Dataframe mit allen Saisons extrahiert. Damit können die Spieler für die gewählte Liga und Saison ausgewählt werden.
def get_data_by_league_and_season(preloaded_data_df, league, season):
# Filter the dataframe for the given league and season
filtered_df = preloaded_data_df[(preloaded_data_df['league'] == league) & (preloaded_data_df['season'] == season)]
if not filtered_df.empty:
# Assuming there's only one row per league-season combination
return filtered_df.iloc[0]['data']
else:
# Handle case where no data is found for the given league and season
print(f"No data found for league: {league}, season: {season}")
return None
Die Sidebar wird mit den Filteroptionen erstellt:
# Header with logo and app name placeholder
st.sidebar.image('images/logo.jpg', use_column_width=True)
# Dictionary für Filteroptionen erstellen
leagues = helpers.create_leagues_dict_with_flags()
seasons = helpers.create_seasons_dict()
quality = helpers.create_quality_dict()
# Sidebar-Einstellungen
st.sidebar.header('Spieler auswählen:', divider=True)
selected_league_display = st.sidebar.selectbox('Wettbewerb', options=list(leagues.keys()))
selected_season_display = st.sidebar.selectbox('Saison', options=list(seasons.keys()))
# Zugriff auf die tatsächlichen Werte
selected_league = leagues[selected_league_display]
selected_season = seasons[selected_season_display]
# Dataframe welcher geladen werden soll
data = helpers.get_data_by_league_and_season(dataframe, selected_league, selected_season)
# Formular zur Spielerauswahl in der Seitenleiste
position = st.sidebar.selectbox('Position', ['Abwehrspieler', 'Außenverteidiger', 'Mittelfeldspieler', 'Flügelspieler', 'Angreifer'])
# Spieler aus Dataframe laden und Filter für Position
players =sorted(data[data['position'] == position]['player_name'])
# Auswahl in der Sidebar
player = st.sidebar.selectbox('Spieler', players)
# Auswahl der Qualität
selected_quality_display = st.sidebar.selectbox('Qualität', options=list(quality.keys()))
selected_quality = quality[selected_quality_display]
Die Dictionaries leagues, seasons und quality werden in der Datei utils/helpers.py definiert. Sie enthalten die Namen der Ligen, Saisons und Qualitäten, die in der Sidebar angezeigt werden sollen, damit nicht die internen Namen der Variabel aus der Datenbank verwendet werden müssen.
Der Key ist der Name, der dem Nutzer angezeigt wird und der Value ist der interne Name, der in der Datenbank verwendet wird. Beispielhaft für die Saisons:
def create_seasons_dict():
seasons = {
"2023/24": "2023_2024",
"2022/23": "2022_2023"
}
return seasons
Der Hauptteil der Anwendung wird mit dem Streamlit-Befehl st.header erstellt. Hier kommt der eigentliche Inhalt der Seite. In diesem Fall die Bewertung eines Spielers mit einem Plot und der Beschreibung der Bewertung.
# Main content area
st.header('Bewertung von ' + player + ' ' + selected_quality_display, divider=True)
# Variablen übergeben die geplottet werden sollen
attributes = helpers.get_attributes_details(selected_quality, position)
# Plot erstellen
chart = plots.create_player_plot(data, attributes, player, position, selected_league_display, selected_season_display, selected_quality_display)
st.altair_chart(chart, use_container_width=True)
# Beschreibung der Spielerbewertung
with st.spinner('Schreibe Spielerbewertung...'):
st.write('🏴')
evaluation = get_player_evaluation(player, attributes, data)
st.success(evaluation)
# Beschreibung der Spielerbewertung
with st.spinner('Schreibe Spielerbewertung...'):
st.write('🇩🇪')
evaluation = get_player_evaluation_german(player, attributes, data)
st.success(evaluation)
# Footer
st.markdown('---') # This creates a horizontal line
st.write('This Webapp was created by Christoph Debowiak - [chrisdebo @GitHub](https://github.com/chrisdebo)')
Die Funktion get_attributes_details wird in der Datei utils/helpers.py definiert und gibt die Attribute zurück, die für die gewählte Qualität und Position relevant sind. Je nach Position und Qualität können die Attribute variieren. Für Angreifer sind andere Qualitäten wichtiger als für Abwehrspieler.
def get_attributes_summary(position) -> list:
if position == 'Abwehrspieler':
a = ['involvement_z', 'progression_z', 'composure_z', 'aerial_threat_z', 'defensive_heading_z',
'active_defense_z', 'intelligent_defense_z']
elif position == 'Mittelfeldspieler':
a = ['involvement_z', 'progression_z', 'passing_quality_z', 'providing_teammates_z', 'box_threat_z',
'active_defense_z', 'intelligent_defense_z', 'effectiveness_z']
elif position == 'Angreifer':
a = ['involvement_z', 'pressing_z', 'run_quality_z', 'finishing_z', 'poaching_z',
'aerial_threat_z', 'providing_teammates_z', 'hold_up_play_z']
elif position == 'Flügelspieler':
a = ['involvement_z', 'passing_quality_z', 'providing_teammates_z', 'dribble_z', 'box_threat_z',
'finishing_z', 'run_quality_z', 'pressing_z', 'effectiveness_z']
elif position == 'Außenverteidiger':
a = ['involvement_z', 'progression_z', 'passing_quality_z', 'providing_teammates_z', 'run_quality_z',
'active_defense_z', 'intelligent_defense_z']
else:
a = []
return a
Visualisierung der Ergebnisse: Plots
Es gibt unzählige Möglichkeiten Daten zu visualisieren. Im Fußballbereich haben sich dabei Radar- und Distributionsplots als sehr beliebt erwiesen.
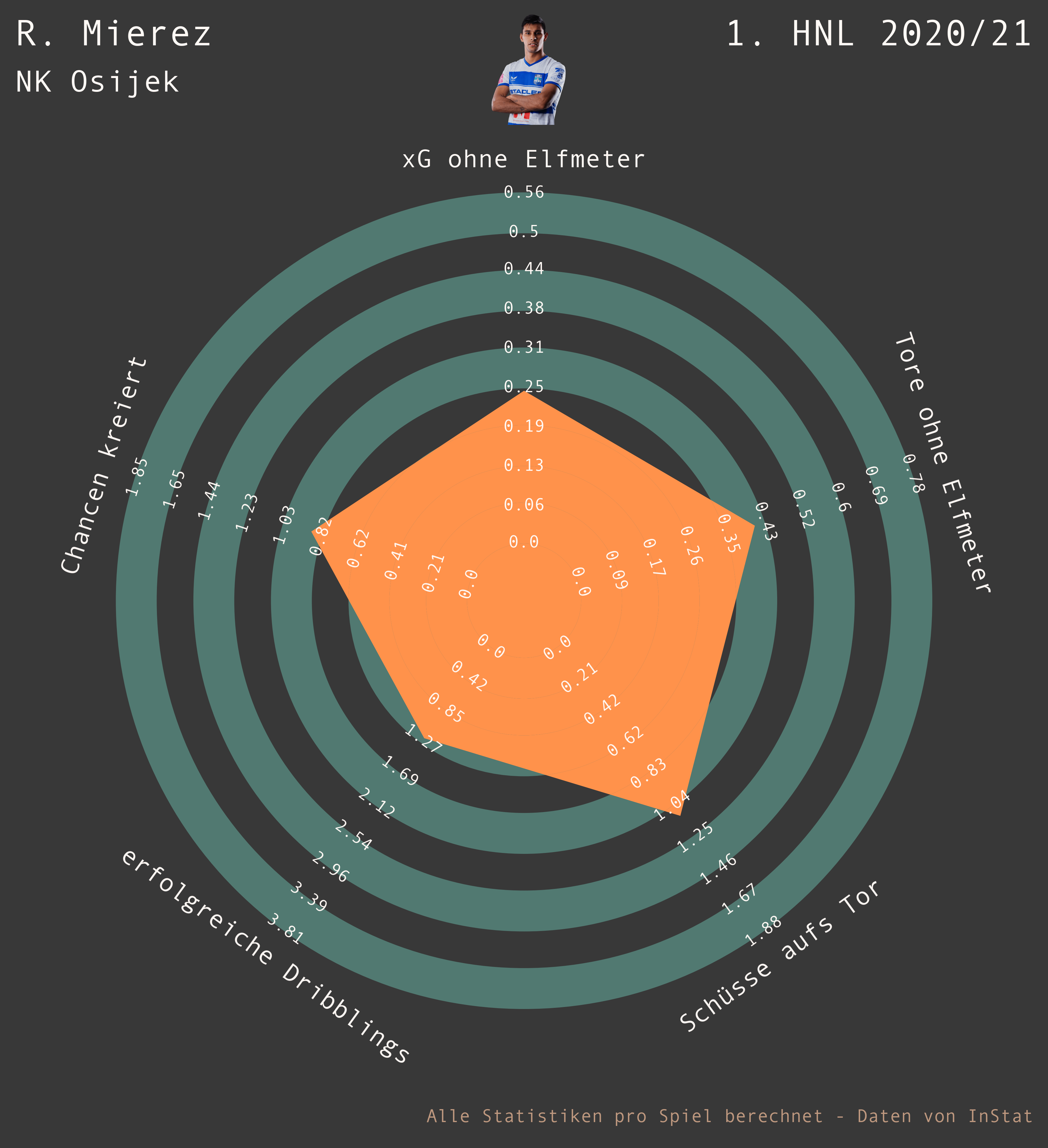
Radarplots
Hier eines meiner ersten Radarplots von 2021 aus einer meiner Spielerbewertungen:
Distributionsplots
Mittlerweile finde ich Distributionsplots (manchmal auch Verteilungsplot oder Beeplot genannt) vorteilhafter, da sie mehr Informationen auf einmal liefern. Der Nutzer kann direkt sehen, wie ein Spieler im Verhältnis zu anderen Spielern performt hat.
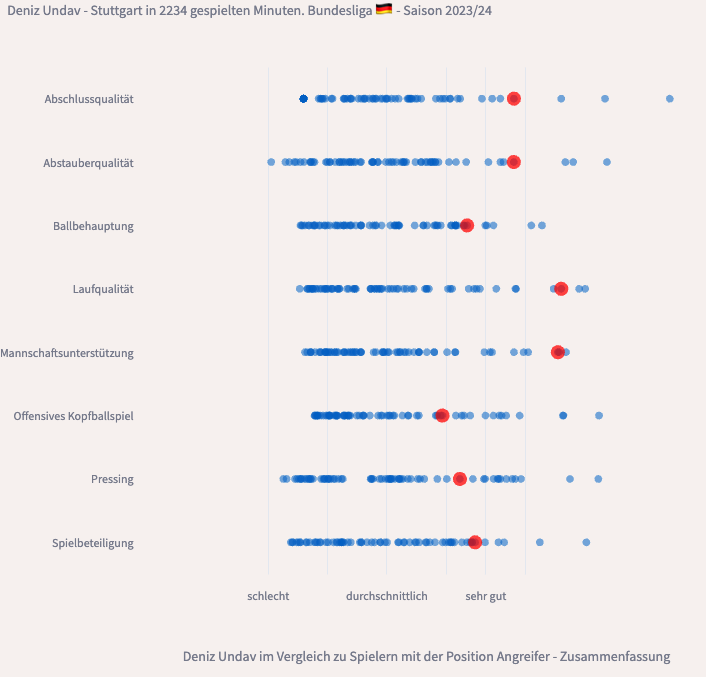
Codebeispiel Plots
Die Plots werden in der Datei utils/plots.py definiert. Hier ein Beispiel für Distributionplot.
Die Funktion create_player_plot erstellt einen Plot für einen spezifischen Spieler, der die Attribute des Spielers mit anderen Spielern in der gleichen Position vergleicht.
Es wird das Dataframe mit allen Daten der jeweiligen Saison und des Wettbewerbs benötigt. Es wird der Spielername, die Position, der Wettbewerb, die Saison und die Qualität benötigt, um den Plot zu erstellen.
Standardmäßig wird als Qualität „Zusammenfassung“ ausgewählt, was dann positionsabhängige Qualitäten übergibt.
Ausgegeben wird ein Altair-Chart-Objekt, das dann in der Streamlit-Anwendung angezeigt wird.
Zuerst werden die Labels für die X- und Y-Achse erstellt. Dann wird das Dataframe für den ausgewählten Spieler und die Spieler auf der gleichen Position gefiltert.
def create_player_plot(data: pd.DataFrame, attributes: list[str], player_name: str, position: str, league: str, season: str, quality: str) -> alt.Chart:
"""
Creates a plot for a specific player, comparing their attributes to other players in the same position.
Parameters:
data (pd.DataFrame): The dataset containing player information.
attributes (List[str]): A list of attributes to be used for evaluating the player.
player_name (str): The name of the player.
position (str): The position of the player.
league (str): The league in which the player plays.
season (str): The season for which the data is being analyzed.
quality (str): The quality metric used for player evaluation.
Returns:
alt.Chart: An Altair chart object representing the player plot.
"""
x_labels = utils.helpers.create_x_labels()
y_labels = utils.helpers.create_y_labels()
# Daten für den ausgewählten Spieler filtern
player_data = data[(data['player_name'] == player_name) & (data['position'] == position)]
# Daten für alle Spieler auf der gleichen Position filtern
position_data = data[data['position'] == position]
Nun werden die Daten die geplottet werden sollen, in ein Dataframe geladen, da das Altair-Framework erlaubt die Daten direkt aus einem Dataframe zu plotten. Zuerst werden die Daten dafür vorbereitet. Es werden alle Attribute/Qualitäten für alle Spieler iteriert. Dabei wird der Rang des Spielers und die Gesamtanzahl der Spieler berechnet und in einer neuen Spalte gespeichert. Alle Informationen werden zuerst in der Liste plot_data_list aneinandergereiht und später in das Dataframe plot_data überführt.
# Erstelle einen DataFrame für das Plotten
plot_data_list = []
for idx, attribute in enumerate(attributes):
temp_data = pd.DataFrame({
'Player': position_data['player_name'],
'Value': position_data[attribute].values.flatten(), # Sicherstellen, dass die Daten 1-dimensional sind
'Attribute': attribute,
'Y': y_labels[attribute] # Y-Wert als benutzerdefiniertes Label zuweisen
})
temp_data['Rank'] = temp_data['Value'].rank(ascending=False, method='min')
temp_data['Total'] = len(temp_data)
temp_data['Rank_Display'] = temp_data.apply(lambda row: f"{int(row['Rank'])}/{int(row['Total'])}", axis=1)
plot_data_list.append(temp_data)
plot_data = pd.concat(plot_data_list)
Hier wird der erste Chart erzeugt mit allen Spielern und den Attributen. Der Chart wird mit einem Kreis für jeden Spieler und einem Tooltip erstellt, der die Spielerinformationen anzeigt. Die Datengrundlage ist plot_data. Jede Qualität ist dabei wie ein eigener Chart. Der z-Score wird auf der x-Achse dargestellt. Der y-Wert ist das Attribut. Der Tooltip zeigt den Spieler und den Rang an.
# Erstelle den Altair-Plot
base = alt.Chart(plot_data).mark_circle(size=60, opacity=0.5).encode(
x=alt.X('Value:Q', scale=alt.Scale(domain=(-3, 4)),
axis=alt.Axis(title=f"{player_name} im Vergleich zu Spielern mit der Position {position} - {quality}",
titleY=75, titleAlign='center', values=list(x_labels.keys()),
labelExpr="datum.value == -1.5 ? 'schlecht' : datum.value == -0.75 ? 'unterdurchschnittlich' : datum.value == 0 ? 'durchschnittlich' : datum.value == 0.75 ? 'gut' : datum.value == 1.25 ? 'sehr gut' : datum.value == 1.75 ? 'überragend' : ''")),
y=alt.Y('Y:N', axis=alt.Axis(
title=f'{player_data["player_name"].values[0]} - {player_data["team_name"].values[0]} in {player_data["minutes_played"].values[0]} gespielten Minuten. {league} - Saison {season} ',
titleAngle=0, titleX=100, titleY=-50, labelAngle=0, labelAlign='right', labelLimit=175)),
# Y-Achse mit Attributnamen und Beschriftung
tooltip=['Player', 'Rank_Display']
).properties(
width=700,
height=85 * len(attributes)
)
Nun wird der ausgewählte Spieler hervorgehoben. Dafür wird ein neuer Chart erstellt, der nur den ausgewählten Spieler hervorhebt. Der Chart wird mit einem roten Kreis erstellt und zeigt den Spieler und den Rang an.
# Hervorhebung des ausgewählten Spielers
highlight_data_list = []
for idx, attribute in enumerate(attributes):
temp_data = pd.DataFrame({
'Player': [player_name],
'Value': [player_data[attribute].values.flatten()[0]],
'Attribute': [attribute],
'Y': [y_labels[attribute]]
})
temp_data['Rank'] = \
plot_data[(plot_data['Attribute'] == attribute) & (plot_data['Player'] == player_name)]['Rank'].values[0]
temp_data['Total'] = \
plot_data[(plot_data['Attribute'] == attribute) & (plot_data['Player'] == player_name)]['Total'].values[0]
temp_data['Rank_Display'] = f"{int(temp_data['Rank'][0])}/{int(temp_data['Total'][0])}"
highlight_data_list.append(temp_data)
highlight_data = pd.concat(highlight_data_list)
highlight = alt.Chart(highlight_data).mark_circle(size=200, color='red').encode(
x='Value:Q',
y=alt.Y('Y:N', axis=alt.Axis(labels=True)),
tooltip=['Player', 'Rank_Display']
)
Zuletzt werden die beiden Charts kombiniert und die Farben der Skalen unabhängig voneinander gesetzt.
# Kombiniere den Basis-Chart und Highlight-Chart
chart = alt.layer(base, highlight).properties(
#background='#f0f0f0' # Hintergrundfarbe setzen
).resolve_scale(
color='independent'
)
return chart
Large Language Models
Durch die aktuelle Entwicklung von Large Language Models wie GPT etc. ist es möglich die Daten auch direkt in einer benutzerfreundlichen Sprache auszugeben. Durch die Entwicklung von dafür generierten Prompts, wird dem Nutzer die Möglichkeit gegeben, die Daten in natürlicher Sprache zu erhalten. Diese Berichte geben einen ersten Überblick über den Spieler und können als Grundlage für weitere Analysen dienen. Für Implementierung solcher KI generierten Texte habe ich mich an der Idee von David Sumpter und seinem Projekt „twelve“ orientiert, wie er es in dem Vortrag dazu in der twelve-Community mit dem Titel „Using large language models for scouting“ vorgestellt hat.
Codebeispiel Textausgabe
Ich übergebe den Spielernamen, die Qualitäten die beschrieben werden sollen und das Dataframe mit den Daten. Die Funktion gibt dann eine Beschreibung des Spielers zurück als String. Wichtig ist hier, dass wir dem LLM einen vernünftigen prompt übergeben. Dieser setzt sich hier aus mehreren Informationen zusammen.
Zuerst werden alle Qualitäten des Spielers in einer Schleife durchlaufen und die Beschreibung für jede Qualität erstellt. Diese Beschreibungen werden dann in der Variable player_description gespeichert.
Da das LLM mit z-Scores nicht viel anfangen kann, muss der z-Score in eine Beschreibung umgewandelt werden. Dafür wird die Funktion describe_level_german verwendet, die den z-Score in eine Beschreibung umwandelt.
def describe_level_german(z_score: float) -> str:
if z_score >= 1.5:
description = "überragend"
elif z_score >= 1:
description = "ausgezeichnet"
elif z_score >= 0.5:
description = "gut"
elif z_score >= -0.5:
description = "durchscnitlich"
elif z_score >= -1:
description = "unterdurchschnittlich"
else:
description = "schlecht"
return description
def get_player_evaluation_german(player_name: str, attributes: list, data: pd.DataFrame) -> str:
"""
Generates an evaluation of a player based on their attributes and data.
Parameters:
player_name (str): The name of the player.
attributes (list): A list of attributes to be used for evaluating the player.
data (pd.DataFrame): The DataFrame containing the player data.
Returns:
str: A description of the player based on their attributes and data.
"""
try:
player_data = data[data['player_name'] == player_name].iloc[0]
position = player_data['position']
except IndexError:
return f"No data found for player {player_name}"
description = f"Player: {player_name}\n"
player_description = ""
for attribute in attributes:
z_score = player_data.get(attribute, None)
if z_score is None:
return f"Attribute {attribute} not found for player {player_name}"
level = describe_level_german(z_score)
player_description += f"Wenn es um die Fähigkeit {attribute} geht, dann ist {player_name} {level}.\n"
Nun wird dem Chatbot eine Rolle zugewiesen:
messages = [
{"role": "system", "content": f"Du bist ein Fußballscout aus Deutschland \
Du lieferst prägnante und auf den Punkt gebrachte Zusammenfassungen von Fußballspielern \
basierend auf Daten. Du sprichst und benutzt für den Fußball typische Sprache. \
Du nutzt die Informationen aus den dir gegebenen Daten und Antworten \
aus früheren 'user/assistant' Paaren, um Zusammenfassungen über die Spieler zu erstellen. \
Deine aktuelle Aufgabe besteht darin einen bestimmten Spieler auf der Position {position} zu beschreiben."},
{"role": "user", "content": "Was meinst du genau mit Fußball?"},
{"role": "assistant", "content": "Ich meine die Sportart Fußball, welche in Europa und in Deutschland die beliebteste und bekannteste Sportart ist. \
"}]
Und schließlich wird der gesamte prompt zusammengeführt und an das LLM übergeben. Die seed Variable sorgt dafür, dass die Antwort immer gleich bleibt, wenn der gleiche seed verwendet wird. Die Temperatur bestimmt, wie kreativ die Antwort ist. Je höher die Temperatur, desto kreativer die Antwort. Weitere Informationen dazu findest du in der OpenAI Dokumentation.
start_prompt ="Hier findest du eine Beschreibung einiger Fähigkeiten des Spielers:\n\n"
end_prompt = f"\n Nutze die zur Verfügung stehenden Daten und mache eine Zusammenfassung über den Spieler (nicht mehr als drei Sätze) und spekuliere über die Rolle, welche dieser Spieler in einem Team haben könnte aufgrund dieser Fähigkeiten: {', '.join(attributes)}"
#Now ask about current player
the_prompt = start_prompt + player_description + end_prompt
user={"role": "user", "content": the_prompt}
messages = messages + [user]
response = client.chat.completions.create(
model="gpt-4o", # You can use other models as well
messages=messages,
seed=42,
temperature=0.5
)
return response.choices[0].message.content
Als Antwort erhalten wir einen Text, der den Spieler beschreibt und die Rolle, die er in einem Team haben könnte.
