Datenbank
Während HDF5-Dateien für die Speicherung großer numerischer Datensätze und für wissenschaftliche Anwendungen nützlich sind, bieten Datenbanken umfassendere Funktionen für Datenabfragen, Integrität, Sicherheit und Skalierbarkeit. Der wichtigste Faktor ist jedoch, dass mit einer Datenbank das Projekt und die Daten von mehreren Personen gleichzeitig genutzt werden können und von überall auf der Welt darauf zugegriffen werden kann.
Ebenfalls ist es bei den Dateigrößen unmöglich eine Webanwendung zu entwickeln, die auf HDF5-Dateien basiert. Unsere aktuellen Dateien haben bisher folgende Größen:
spadl.h5: 11.06 GBlabels.h5: 128 MBfeatures.h5: 8.39 GBpredictions.h5: 270 MB
Bei der Datenbank handelt es sich um eine relationale Datenbank, die aus mehreren Tabellen besteht. Die Tabellen sind miteinander verknüpft und können über Abfragen (SQL) abgerufen werden. ich habe mich für MariaDB entschieden, da es eine Open-Source-Alternative zu MySQL ist und eine hohe Kompatibilität aufweist.
Datenbankstruktur
Hier möchte ich die Struktur der Datenbank anhand der Bundesligasaison 2023/24 erläutern.
Tabellen für alle Ligen und Saisons
Die Datenbank besteht aus folgenden Tabellen, die für alle Ligen und Saison universal sind:
teams: Enthält Informationen zu den Teams. (team_id, team_name)players: Enthält Informationen zu den Spielern. (player_id, player_name)result: Enthält Informationen zu dem Ergebnis eines Events. (result_id, result_name)bodypart: Enthält Informationen zu dem Körperteil, mit dem ein Spieler den Ball berührt. (bodypart_id, bodypart_name)actiontypes: Enthält Informationen zu den Aktionen eines Spielers. (actiontype_id, actiontype_name)competitions: Enthält Informationen zu den Wettbewerben. (competition_id, competition_name, country_id, season_id, season_name, …)
Tabellen für die Bundesliga-Saison 2023/24
Auf diese oben genannten Tabellen wird in den folgenden Tabellen referenziert:
bundesliga_2023_2024_actions: Enthält Informationen zu allen Aktionen in der Bundesliga-Saison 2023/24. (original_event_id, action_id, game_id, team_id, player_id, result_id, bodypart_id, actiontype_id, start_x, start_y, time_seconds, …)bundesliga_2023_2024_games: Enthält Informationen zu allen Spielen in der Bundesliga-Saison 2023/24. (game_id, competition_id, season_id, game_date, home_team_id, away_team_id, home_score, away_score, …)bundesliga_2023_2024_player_games: Enthält Informationen zu allen Spielern und den gespielten Minuten, sowie der Startposition für jedes Spiel. (game_id, player_id, team_id, is_starter, starting_position, minutes_played)bundesliga_2023_2024_stats_z: Enthält Informationen für jeden Spieler zu allen z-Scores der Basisstatistiken und Qualitäten. (player_id, team_id, minutes_played, goals, assists, shots, passes, tackles, interceptions, …)
Aus diesen Tabellen können dann Abfragen erstellt werden, um die gewünschten Informationen zu erhalten. Aufgrund der Größe der Datenbank und der Anzahl der Tabellen, ist es wichtig, dass die Datenbank gut strukturiert ist und die Abfragen effizient sind. Viele joins können die Performance der Datenbank beeinträchtigen, weshalb ich mich teilweise für eine denormalisierte Datenbank entschieden habe (stats_z). Hieraus ergibt sich in der Praxis eine viel höhere Abfragegeschwindigkeit und der zusätzliche Speicherplatz ist in der heutigen Zeit kein Problem mehr.
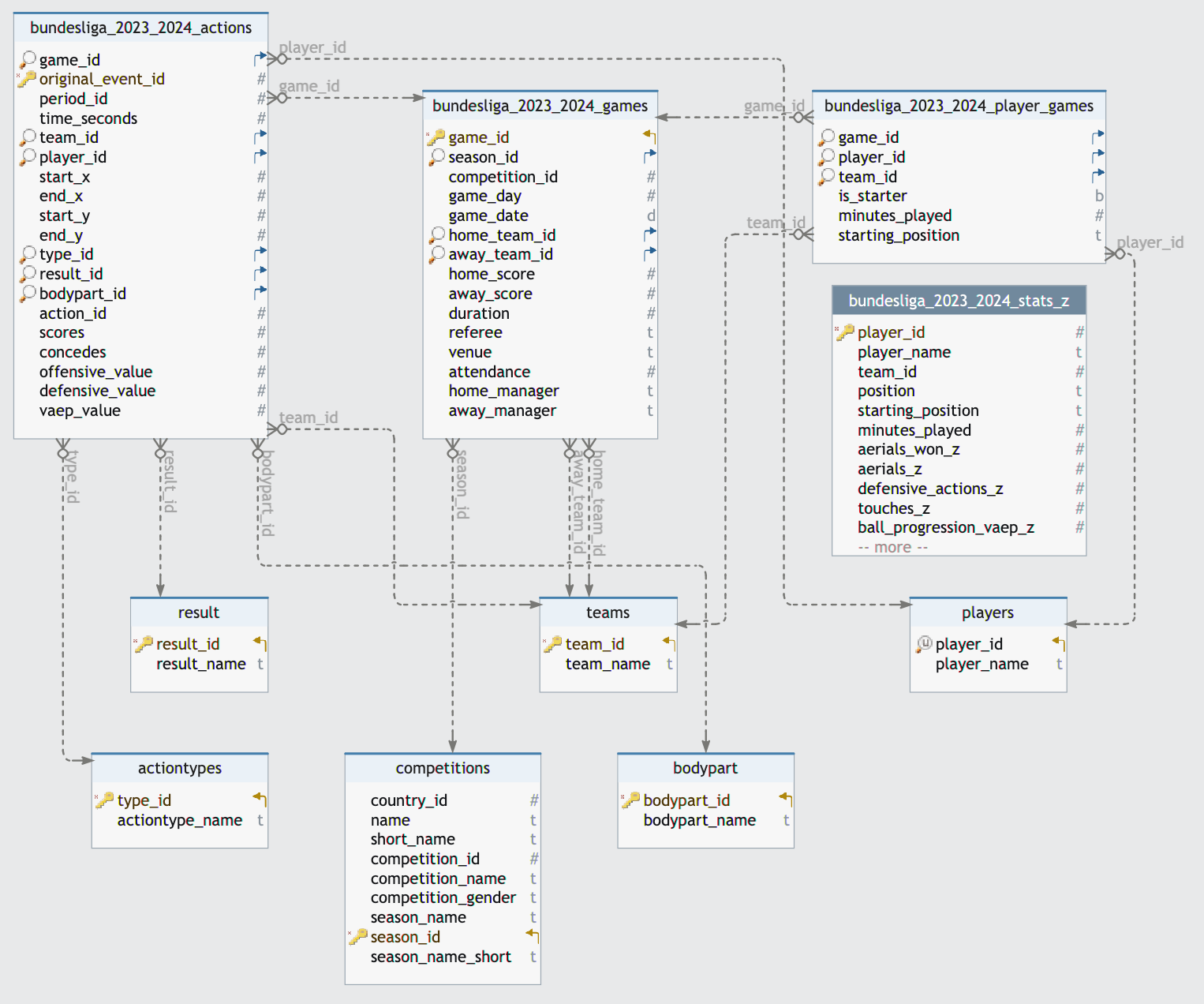
Auszug aus der Datenbank
Hier visuell die Struktur der Datenbank für die Bundesliga-Saison 2023/24:
Datenbankzugriff - Werte speichern
Der Zugriff auf die Datenbank erfolgt über Python und die Bibliothek sqlalchemy. Hier ein Beispiel, wie auf die Datenbank zugegriffen werden kann und neue Werte gespeichert werden. Um Rechenkapazität und Zeit zu sparen, werden nur die neuen Daten in der Tabelle gespeichert.
Dazu werden die Primärschlüssel der Tabellen verwendet, um zu überprüfen, ob die Daten bereits in der Datenbank vorhanden sind.
Bei Tabellen ohne Primärschlüssel müsste jeder Eintrag mühselig überprüft werden, ob er bereits in der Datenbank vorhanden ist. Da ist es oft schneller alle Daten neu zu übertragen, was jedoch fehleranfälliger ist.
Der Connections-String wird in eigenen Dateien gespeichert, um die Zugangsdaten nicht im Code zu speichern und wird dann mit der Funktion create_connection_string() geladen.
def write_to_sql_efficient(*args) -> None:
"""
Writes data from a Pandas DataFrame to an SQL table, checking for duplicates directly in the database.
Parameters:
- dataframe: The DataFrame to be written to the SQL table.
- table_name: The name of the target table in the SQL database.
- connection_string: The connection string to the SQL database.
- primary_key_column: The name of the column to be used as the primary key for checking duplicates.
"""
# Verbindung zur Datenbank herstellen mit pool_pre_ping=True
connection_string = create_connection_string()
engine = create_engine(connection_string, pool_pre_ping=True)
for dataframe, table_name, primary_key_column in args:
# SQL-Abfrage vorbereiten, um Duplikate direkt in der Datenbank zu überprüfen
sql_query = f"SELECT {primary_key_column} FROM {table_name}"
existing_primary_keys = pd.DataFrame(engine.connect().execute(text(sql_query)))
# Überprüfen, ob beide DataFrames nicht leer sind
if not dataframe.empty and not existing_primary_keys.empty:
# Nur neue Datensätze auswählen, die nicht bereits in der Datenbank vorhanden sind
new_data = pd.merge(dataframe, existing_primary_keys, on=primary_key_column, how='left',
indicator=True).query('_merge == "left_only"').drop('_merge', axis=1)
else:
new_data = dataframe
# Wenn es neue Datensätze gibt, diese in die SQL Tabelle schreiben
if not new_data.empty:
new_data.to_sql(table_name, engine, index=False, if_exists='append')
print(f"{len(new_data)} Datensätze wurden erfolgreich in die Tabelle {table_name} eingefügt.")
else:
print("Keine neuen Datensätze zum Einfügen gefunden. Tabelle:" + table_name)
Datenbankzugriff - Werte laden
Um Werte aus der SQl Tabelle in ein Dataframe zu laden, kann folgender Code verwendet werden:
def load_actions_from_sql(league: str, season: str) -> pd.DataFrame:
"""
Loads actions from an SQL table.
Parameters:
- league: The league of the actions.
- season: The season of the actions.
Returns:
DataFrame: A DataFrame containing the actions.
"""
# Verbindung zur Datenbank herstellen
# 'engine' ist ein SQLAlchemy Engine-Objekt, das für die Verbindung zur Datenbank verwendet wird
connection_string = create_connection_string()
engine = create_engine(connection_string, pool_pre_ping=True)
# Generate the table name from the league and season parameters
table_name = f"{league}_{season}_actions"
# Laden der existierenden Daten aus der SQL-Tabelle
try:
sql_query = f"SELECT * FROM {table_name}"
existing_data = pd.DataFrame(engine.connect().execute(text(sql_query)))
except Exception as e:
print(f"Fehler beim Laden der Daten: {e}")
existing_data = pd.DataFrame()
return existing_data
SQL Tabellen mit Python automatisch erstellen
Da wir jede beliebe SQL Abfrage mit Python übermitteln können, ist es auch möglich die Tabellen direkt mit Python zu erstellen. Mit jeder Saison und Liga kommen 4 neue Tabellen hinzu, die erstellt werden müssen. Bei 13 Wettbewerben pro Saison kann das schnell zeitaufwendig werden.
Hier als Beispiel eine Funktion um eine Tabelle zu erstellen mit den Spieleraktionen:
def create_actions_table(connection, prefix, season):
table_name = f"{prefix}_{season}_actions"
# Überprüfen, ob die Tabelle bereits existiert
check_table_exists = f"""
SELECT COUNT(*)
FROM information_schema.tables
WHERE table_schema = '{DATABASE}'
AND table_name = '{table_name}';
"""
result = connection.execute(text(check_table_exists)).scalar()
if result:
print(f"Tabelle '{table_name}' existiert bereits.")
return
create_sql = f"""
CREATE TABLE IF NOT EXISTS `{table_name}` (
`game_id` bigint(20) DEFAULT NULL,
`original_event_id` bigint(20) NOT NULL,
`period_id` int(20) DEFAULT NULL,
`time_seconds` float DEFAULT NULL,
`team_id` int(20) DEFAULT NULL,
`player_id` int(11) DEFAULT NULL,
`start_x` float DEFAULT NULL,
`end_x` float DEFAULT NULL,
`start_y` float DEFAULT NULL,
`end_y` float DEFAULT NULL,
`type_id` int(20) DEFAULT NULL,
`result_id` int(20) DEFAULT NULL,
`bodypart_id` int(20) DEFAULT NULL,
`action_id` int(20) DEFAULT NULL,
`scores` float DEFAULT NULL,
`concedes` float DEFAULT NULL,
`offensive_value` float DEFAULT NULL,
`defensive_value` float DEFAULT NULL,
`vaep_value` float DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
"""
connection.execute(text(create_sql))
# Füge die Indizes hinzu
alter_sql1 = f"""
ALTER TABLE `{table_name}`
ADD PRIMARY KEY (`original_event_id`),
ADD KEY `fk_game_{table_name}` (`game_id`),
ADD KEY `fk_team_{table_name}` (`team_id`),
ADD KEY `fk_player_{table_name}` (`player_id`),
ADD KEY `fk_type_{table_name}` (`type_id`),
ADD KEY `fk_result_{table_name}` (`result_id`),
ADD KEY `fk_bodypart_{table_name}` (`bodypart_id`);
"""
connection.execute(text(alter_sql1))
# Füge die Fremdschlüssel hinzu, und stelle sicher, dass sie korrekt auf andere Tabellen verweisen
alter_sql2 = f"""
ALTER TABLE `{table_name}`
ADD CONSTRAINT `fk_bodypart_{table_name}` FOREIGN KEY (`bodypart_id`) REFERENCES `bodypart` (`bodypart_id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
ADD CONSTRAINT `fk_game_{table_name}` FOREIGN KEY (`game_id`) REFERENCES `{prefix}_{season}_games` (`game_id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
ADD CONSTRAINT `fk_player_{table_name}` FOREIGN KEY (`player_id`) REFERENCES `players` (`player_id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
ADD CONSTRAINT `fk_result_{table_name}` FOREIGN KEY (`result_id`) REFERENCES `result` (`result_id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
ADD CONSTRAINT `fk_team_{table_name}` FOREIGN KEY (`team_id`) REFERENCES `teams` (`team_id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
ADD CONSTRAINT `fk_type_{table_name}` FOREIGN KEY (`type_id`) REFERENCES `actiontypes` (`type_id`) ON DELETE NO ACTION ON UPDATE NO ACTION;
"""
connection.execute(text(alter_sql2))
print(table_name + ' erstellt.')
Und schließlich die Funktion um alle Tabellen zu erstellen. Hierbei wird die Tabelle competitions ausgelesen und für jede Saison und Liga aus der Datei die Tabellen erstellt.
def create_database_tables():
competitions = pd.read_json('../competitions.json')
connection_string = db.db_connection.create_connection_string()
engine = create_engine(connection_string)
with engine.connect() as connection:
connection.execute(text('SET FOREIGN_KEY_CHECKS=0;'))
for index, row in competitions.iterrows():
prefix = row['db_prefix']
season = row['season_name'].replace("-", "_")
create_tables(connection, prefix, season, create_vaep=False, create_player_games=False, create_games=False,
create_actions=False, create_player_statistics_z=True)
connection.execute(text('SET FOREIGN_KEY_CHECKS=1;'))
Die Einträge in der competitions.json Datei sehen dabei wie folgt aus. Hierbei wird db_prefix benötigt, um die Tabellen zu erstellen.
[
{
"country_id":81,
"name":"Germany",
"short_name":"GER",
"competition_id":3,
"competition_name":"Bundesliga",
"competition_gender":"Male",
"season_name":"2023-2024",
"season_id":23243,
"season_name_short":"2324",
"db_prefix":"bundesliga"
}
]